
Untuk sebagian orang, istilah web crawler mungkin cukup asing untuk didengar. Tetapi, bagi yang memahami SEO, kamu pasti tahu seberapa penting peran web crawler dalam menampilkan sebuah website pada search engine. Selain itu, bot yang satu ini juga memiliki beberapa fungsi lainnya yang sangat bermanfaat bagi user.
Lantas, apakah yang sebenarnya dimaksud dengan web crawler? Bagaimana bot ini bisa sangat berperan penting bagi sebuah website? Yuk, mari kita cari tahu jawabannya pada pembahasan kali ini mengenai pengertian hingga cara kerja dari web crawler itu sendiri. Simak artikelnya sampai akhir ya, happy reading!
Pengertian
Web crawler atau dikenal juga sebagai spider merupakan sebuah bot yang berfungsi untuk melakukan pencarian dan mengindeks berbagai informasi mengenai halaman web (webpage) di internet. Terutama informasi pada website, seperti URL, konten, meta tag, dan informasi lainnya yang relevan. Selain itu, web crawler juga bertanggung jawab untuk lebih memahami apa isi dari website tersebut. Nantinya, berbagai informasi yang telah diperoleh akan disimpan pada database search engine. Sehingga, ketika ada yang melakukan pencarian pada search engine, maka informasi yang dibutuhkan dapat ditampilkan dengan mudah.
Lalu, perlu diketahui juga bahwa bot ini dioperasikan oleh search engine, seperti Google, Bing, ataupun Yahoo, berdasarkan algoritmanya masing-masing. Algoritma ini dapat membantu bot menemukan informasi relevan dalam menanggapi permintaan pencarian. Caranya, bot akan melakukan pencarian (crawl), mengategorikan seluruh halaman web yang bisa ditemukan, dan mengindeks halaman yang diminta.
Sederhananya, jika diumpamakan maka web crawler ini layaknya seorang librarian atau pustakawan yang bertugas mengorganisir buku-buku di perpustakaan agar menjadi lebih rapih dan mudah ditemukan oleh para pengunjung. Untuk dapat mengorganisir buku-buku tersebut, maka pustakawan perlu mengetahui detail dari setiap buku agar tempat penyimpanannya bisa disesuaikan berdasarkan kategori.
Nah, berbeda dengan perpustakaan yang terdiri dari bermacam-macam buku sehingga mudah untuk diindeks, pada internet sulit untuk diketahui apakah seluruh informasi sudah terindeks dengan baik atau belum. Oleh karena itu, digunakan web crawler untuk menemukan berbagai informasi yang relevan di internet. Bot akan mulai melakukan pencarian (crawl) dari sebuah website yang sudah diketahui. Selanjutnya, bot akan mengikuti hyperlink yang terdapat di dalam website tersebut ke halaman lainnya, dan begitu seterusnya.
Cara Kerja Web Crawler
Web crawler melakukan indexing untuk webpage dalam jumlah yang tidak terbatas, dikarenakan jumlah webpage yang terdapat di internet juga sangatlah banyak dan akan terus bertambah. Proses ini dimulai dengan mengunjungi daftar URL yang dikenal terlebih dahulu. Kemudian, dari halaman web tersebut akan ditemukan hyperlink yang mengarah ke URL lainnya, dan begitu seterusnya. Sehingga, bot akan terus mengunjungi halaman web, dari satu halaman ke halaman lainnya.
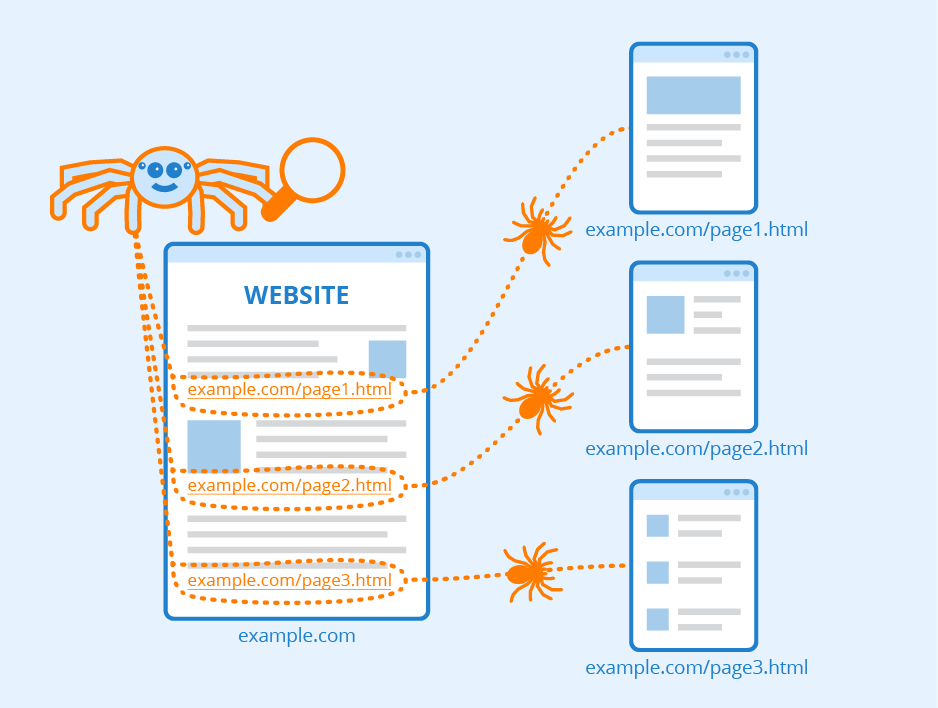
Tetapi, bot ini juga tetap mengikuti beberapa aturan yang ada, sehingga sangat selektif dalam memutuskan website mana yang harus dikunjungi, urutan website yang harus dikunjungi, serta seberapa sering sebuah website harus dikunjungi untuk pengecekan perubahan konten.
Berikut beberapa hal yang dijadikan sebagai bahan pertimbangan untuk mengunjungi sebuah website oleh web crawler.
- Banyaknya tautan yang mengarah pada halaman web, tidak semua website dikunjungi oleh web crawler, hanya website berisikan informasi penting saja dan berkualitas tinggi yang akan dikunjungi untuk indexing. Hal ini ditentukan dari banyaknya website lain yang mengutip website tersebut serta tingkat pengunjung yang dimilikinya. Sehingga, apabila banyak dikutip website lain dan tingkat pengunjungnya cukup tinggi tentu saja bot akan menganggapnya sebagai web berkualitas tinggi.
- Mengunjungi kembali halaman web, tentunya setiap konten pada halaman web akan mengalami perubahan, entah itu file kontennya dipindahkan, diperbarui, ataupun dihapus. Nah, bot akan melakukan pengecekan secara berkala untuk memastikan bahwa setiap konten yang sudah terindex merupakan versi terbaru dari konten tersebut.
- Persyaratan dari Robots.txt, sebelum memutuskan untuk mengunjungi sebuah halaman web, bot akan melakukan pengecekan terhadap file robots.txt yang dihosting oleh web server halaman tersebut. File robots.txt ini berisikan beberapa ketentuan spesifik bagi bot yang mengakses website atau aplikasi yang dihosting. Yaitu, seperti ketentuan mengenai halaman web mana yang dapat dikunjungi, dan link mana yang dapat diikuti.
Jenis-Jenis Web Crawler
Selanjutnya, perlu kamu ketahui bahwa terdapat tiga jenis utama web crawler. Apa sajakah jenisnya? Berikut penjelasannya.
- In-house web crawler, merupakan salah satu jenis crawler yang dikembangkan sendiri oleh sebuah perusahaan untuk melakukan crawling pada website-nya dengan tujuan yang berbeda-beda. Beberapa contoh untuk jenis ini, yaitu Googlebot dan Applebot.
- Commercial web crawler, merupakan jenis crawler yang tersedia secara komersial dan dikembangkan oleh perusahaan penyedia software. Umumnya digunakan oleh beberapa perusahaan besar yang membutuhkan crawler custom untuk kebutuhannya. Contoh untuk jenis commercial, yaitu Swiftbot dan SortSite.
- Open-source web crawler, jenis yang satu ini memiliki sifat open-source dan gratis sehingga siapapun bisa menggunakan dan menyesuaikannya dengan kebutuhan. Meskipun terdapat banyak kekurangan pada fitur dan fungsionalitasnya, tetapi kamu dapat melakukan pengecekan secara langsung ke source code-nya. Contoh untuk jenis open-source, yaitu Apache Nutch dan Open Search Server.
Fungsi Web Crawler
Seperti yang sudah dijelaskan, bahwa bot ini memiliki fungsi utama bagi search engine, yaitu untuk melakukan pencarian serta mengindeks berbagai informasi mengenai website di internet. Selain itu, masih terdapat beberapa fungsi lain yang dimilikinya. Berikut penjelasannya.
- Perbandingan harga, dilakukan oleh beberapa portal untuk mencari dan mengumpulkan informasi mengenai produk tertentu pada sebuah web. Tujuannya adalah agar dapat membandingkan data atau harga dari suatu produk secara akurat.
- Data mining, digunakan untuk mengumpulkan e-mail atau alamat pos perusahaan yang tersedia secara umum.
- Menunjang web analysis tools, berfungsi dalam mencari dan mengumpulkan data untuk page view, incoming dan outbound links. Contoh dari web analysis tools, yaitu Google Search Console.
- Menyediakan informasi, digunakan untuk menyediakan pusat informasi dengan data, misalnya situs berita seperti Google News.
Peran Web Crawler Terhadap SEO
Fungsi utama dari web crawler adalah untuk melakukan pencarian dan mengindeks informasi mengenai website. Nah, jika crawler tidak mengindeks website-mu, maka website tidak akan muncul pada hasil pencarian. Itu berarti mustahil bagi website-mu untuk muncul di peringkat atas pada hasil pencarian di search engine.
Sehingga, penting bagi para pemilik website yang ingin website-nya muncul pada hasil pencarian organik, untuk tidak memblokir web crawler.
Kesimpulan
Sehingga, dapat disimpulkan bahwa web crawler merupakan sebuah bot yang digunakan untuk melakukan pencarian serta mengindeks berbagai informasi di internet. Khususnya, informasi mengenai website, agar dapat diorganisir dan muncul pada hasil pencarian search engine. Dengan begitu, jika ada yang melakukan pencarian di search engine, maka informasi yang diinginkan dapat ditampilkan dengan mudah.
Silakan kunjungi website Wide Host Media untuk mendapatkan berbagai penawaran menarik terkait hosting, server, dan data center. Didukung dengan berbagai teknologi dan insfrastruktur berstandar internasional, sehingga layanan dapat berjalan pada performa terbaik.
Semoga artikel ini bermanfaat.